Como Funcionam os Modelos de Linguagem Multimodais: Embeddings, Visão, Áudio e Raciocínio Unificado
Paulo Coutinho
Portuguese
Avançado
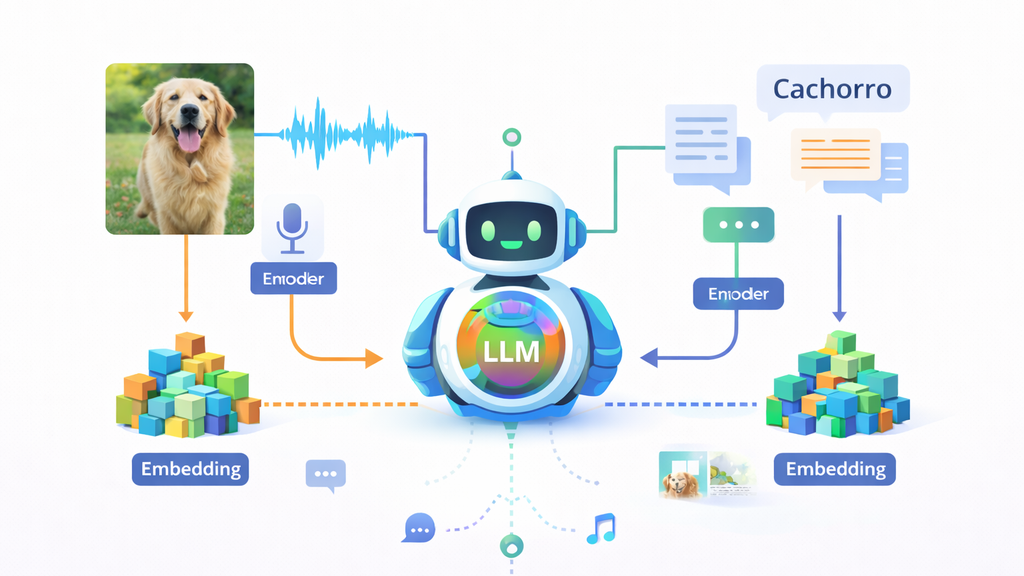
Essa unificação permite que conceitos iguais, vindos de formatos diferentes, fiquem próximos em um mesmo “mapa” matemático. Assim, a palavra escrita “cachorro”, um áudio com a palavra “cachorro” e uma foto de um cachorro podem ser tratados como variações do mesmo conceito. A partir disso, tornam-se possíveis tarefas como descrever uma imagem, relacionar som e texto, e responder perguntas que exigem combinar pistas visuais, auditivas e linguísticas.

Desbloqueie Todo o Conteúdo Premium
Assine agora e tenha acesso ilimitado a todo o conhecimento da plataforma

Artigos Ilimitados
Acesso completo a todos os artigos e tutoriais sem qualquer restrição

Todos os Cursos
Aprenda com todos os cursos criados pela plataforma e acelere sua carreira

Notícias em Primeira Mão
Fique por dentro de todas as novidades e tendências do mercado sem limites
llm multimodal
modelos multimodais
embeddings
inteligência artificial
visão computacional
processamento de áudio
cross-modal reasoning
transformadores
arquitetura de ia
machine learning